SAS 프로그램
확장편집기 윈도우
- 프로그램을 작성하고 편집하는 윈도우
- 풀다운 메뉴의 실행메뉴나 도구상자의 실행아이콘을 클릭하여 프로그램 실행
LOG 윈도우
- SAS가 명령을 수행한 작업 내용을 보여줌
- 프로그램 상 발생한 문법오류, 주의사항, 경고 등을 보여줌
출력 윈도우
- 프로그램 수행의 결과를 보여주는 윈도우
결과
- OUTPUT 윈도우나 GRAPH 윈도우에서 출력되는 결과를 조회 관리
탐색기
- SAS 라이브러리와 데이터 셋을 관리하는 윈도우
SAS 프로그램의 구조
DATA step
- DATA라는 Keyword와 Data Name으로 시작되며, SAS Data Set의 생성 및 자료 값의 계산, 변형 등과 관련된 작업
Procedure step
- PROC 라는 Keyword와 고유 명칭이 부여된 해당 기능을 갖는 Procedure의 이름으로 시작
- Procedure별로 고유한 기능을 가지며, 이와 관련된 자신들만의 명령문 문법을 가짐
SAS 데이터셋 구조
변수(Variable)
- 데이터 셋의 한 열로서 구체적 속성을 나타내는 자료 값들의 집합
- 문자형 변수와 숫자형 변수로 구분
개체(Observation)
- 데이터 셋의 한 행으로서 동일한 관찰 단위에 대한 모든 변수들의 자료 값들의 집합
SAS 명령문
명령문의 구성
중심어(Keyword)
- SAS 명령어로서 DATA, INPUT, IF, CARDS, PROC, RUN 등
이름(Name)
- 변수, Procedure, Data set 등의 고유 명칭
- Name은 영문자, 숫자, _로 이루어지고 이외의 문자 사용 불가
특수문자와 연산자
- $(문자형 변수), ; 등의 특수문자는 고유 기능을 가지고 있으며, 일반적인 연산자(+, - *, /)는 연산을 위해 사용 가능
명령문 형식
- 항상 중심어(Keyword)로 시작하고 ;로 닫는다.
- 한 행은 어느 열에서나 시작할 수 있다. 다음 행으로 한 단어의 잘림이 없이 연속될 수 있고, 한 행에 여러 개의 명령문 사용 가능
- 명령문의 각 원소들은 적어도 하나 이상의 공백에 의하여 구분되어야 함
- 대소문자 구분하지 않음
- 주석은 /* comments */ 또는 *comments;
LIBNAME 명령문
데이터셋 저장
- SAS의 이용 과정에서 생성되고 임시로 WORK 라이브러리에 저장된 SAS Data Set은 특별한 지정이 없는 경우 SAS 종료 시 삭제
- SAS Data Set의 저장을 위해 LIBNAME 명령문을 이용하여 새로은 Library를 만들고 이 곳에 SAS Data Set 저장
1)c:\work\mysasdatDirectory 생성
2) SAS 프로그램 창에서 LIBNAME 명령으로 examdat라는 Library todtjd
LIBNAME examdat "c:\work\mysasdat";3) LIBRARY_NAME.DATA_SET_NAME 형식으로 SAS Data Set 생성
DATA examdat.company;
SET company;
RUN;특징
- LIBNAME 명령문을 이용해 지정된 SAS Library는 SAS가 종료되면 상실되지만 컴퓨터에 저장된 SAS Data Set은 영구히 보관
- 기존에 저장된 SAS Data Set을 새롭게 시작된 SAS Session에서 이용하기 위해서는 Library 다시 지정
Library 이름 생략할 경우 Work라는 Library에 포함된 것으로 간주
데이터 입력
외부 파일에서 읽어 오기
INFILE 명령문
DATA company;
INFILE 'c:\work\mysasdat\company.txt';
INPUT id 1-2 age 3 gender $ 4 item1 5 item2 6 item3 7;
LABEL id='고객번호' age='나이' gender='성별' item1='성능' item2='가격' item3='디자인';
RUN;프로그램 내부 입력
Cards(Datalines) 명령문
DATA data1;
INPUT name $ dept $ date score;
CARDS;
손예진 physics 1223 135
김태리 economic 0705 154
;
RUN;Column Input
해당 글자 위치만큼 데이터 입력 받음
DATA sampledata1;
INPUT classid 1-4 name $ 11-18 class $ 20-23 score 36-38 grade $ 41;
CARDS;
295067048 김떡순 statistics 80.3A
356989087 애호박 mathematics B
704842534 돈까스 30.6C
908727844 english 100 C
424573465 감자튀김 computer science
;
RUN;
PROC PRINT DATA=sampledata1;
RUN;
한 줄에 연속 입력
여러 개의 개체가 줄 구분 없이 연속해서 입력되는 경우 : @@ 사용
DATA sampledata2;
INPUT x y @@;
CARDS;
1 2 3 4 5
6 7 8
9
10
;
RUN;
PROC PRINT DATA=sampledata2;
RUN; 
다양한 할당문 사용
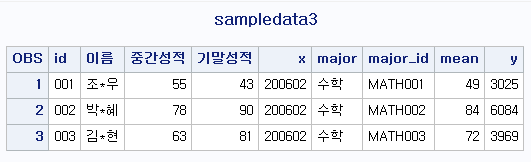
DATA sampledata3;
INPUT id $ name $ mid final;
x=200602; /* Numeric Constant */
major='수학'; /* Character Constant */
major_id='MATH'||id; /* Concatenation */
mean=(mid+final)/2; /* Arithmetic Expression */
y=mid**2; /* Exponentiation */
LABEL name='이름'
mid='중간성적'
final='기말성적';
CARDS;
001 조*우 55 43
002 박*혜 78 90
003 김*현 63 81
;
RUN;
PROC CONTENTS data=sampledata3;
RUN;
PROC PRINT data=sampledata3 LABEL;
RUN;

문자함수 날짜함수
| 형식 | 기능 |
|---|---|
| compress(arg, chars) | arg 내용 중 chars로 주어진 문자 제거 |
| left(arg) | arg 앞 공백 모두 제거 |
| length(arg) | arg 문자열 길이 계산 |
| substr(arg, p, n) | arg의 p번째 문자로부터 n개의 문자열 선택 |
| translate(arg, to, from) | arg 문자열에서 from부분을 to로 변환 |
| trim(arg) | arg의 오른쪽 공백 문자 모두 제거 |
| DAY(date) | date의 값을 구함 (1~31) |
| MDY(minth, day, year) | 연, 월, 일에 해당하는 날짜값 계산 |
| YEAR(date) | date의 연도 구함 |
| WEEKDAY(date) | date의 요일 구함(1~7) |
| TODAY() | 현재 날짜 |
| INTNX('interval, from, n) | from부터 n까지 interval 이후 날짜 계산 |
함수 이용
DATA sampledata4;
INPUT ID $ 1-5 (x1-x3) (1.) enterm enterd;
id=COMPRESS(ID); /* Character Function */
average = MEAN(OF x1-x3); /* Numeric Function */
logx = LOG(x3);
sqrtx = SQRT(x2);
intmean = INT(sqrtx);
max_mf=MAX(x1,x2,x3,4);
ent_day=MDY(enterm,enterd,2020); /* Date Function */
FORMAT ent_day yymmdd6.;
CARDS;
L S A557 2 1
HK H .91 11 5
J MJ 1.3 9 25
CMR 482 4 14
;
RUN;
PROC PRINT DATA=sampledata4;
RUN;

조건문 : IF-THEN-ELSE 명령문
어떤 작업 수행을 모든 관찰치에 대하여 수행하는 것이 아니라 특정 조건에 부합하는 자료만을 처리하기 위한 명령문
IF condition THEN action [ ELSE [ action; ] ]
IN : IF문 사용 시 여러 가의 자료값의 범위를 지정해야 하는 경우 유용하게 사용할 수 있는 option
IF variable IN ( arg1 [,] arg2 [, arg3 , ... ] ) THEN action;
DATA exam;
INFILE 'c:\work\mysasdat\exam.txt';
INPUT id $ name $ mid final;
IF mid>=30 THEN score1='A';
ELSE IF mid>=20 THEN score1='B';
ELSE score1='C';
IF final IN (20 30) THEN score2='B';
IF final IN (40) THEN score2='A';
IF name IN ('Elsa','Anna') THEN sex='F';
IF name IN ('Olaf' 'Kristoff') THEN sex='M';
RUN;
PROC PRINT DATA=exam;
RUN;
DO-END 명령문
DO variable = start TO end BY increment;DO variable = 'chacater1', ..., 'chacatern',
- DO와 END 사이에 있는 명령문 반복 수행
- start는 시작 숫자, end는 마지막 숫자
- BY는 각 단계의 증분 (default=1)
- 수행 과정에서 결과를 저장하기 위해서는 OUTPUT 명령문 사용
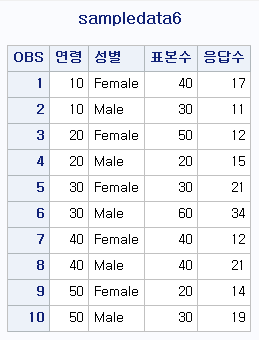
DATA sampledata6;
DO age = 10 TO 50 BY 10;
DO sex = 'Female' , 'Male';
INPUT size response @@;
OUTPUT;
END;
END;
LABEL age='연령' sex='성별'
size='표본수' response='응답수';
CARDS;
40 17 30 11
50 12 20 15
30 21 60 34
40 12 40 21
20 14 30 19
;
RUN;
PROC PRINT DATA=sampledata6 LABEL;
RUN;
OUTPUT 명령문
- DO 명령문 내에서 수행된 결과 Data set에 저장하기 위해 사용
- 여러 개의 Data Set 동시에 만들 경우 사용 가능
Data male female;
SET sampledata6;
IF sex="Male" THEN OUTPUT male; ELSE OUTPUT female;
RUN;- 외부 파일로 출력
DATA sampledata7;
INPUT name $ dept $ one two three four five;
CARDS;
김새스 Stat 1 2 3 4 5
최로그 Epid . 6 7 8 9
이출력 Epid 10 11 12 13 .
박편집 Epid 14 15 . . 16
;
RUN;
DATA _NULL_;
SET sampledata7;
FILE 'c:\work\mysasdat\sampledata7t.txt';
IF dept='Epid';
PUT name 6. ',' @15 four five ',' +5 three two one
RUN;

OUT 명령문
- OUTPUT 명령문과 흔히 함께 사용되며 수행결과에서 얻어지는 정보들로 구성된 새로운 데이터셋 생성시 사용
DATA sampledata8;
INPUT name $ sex $ age height ;
CARDS;
동백 F 34 172
황용식 M 31 182
강종렬 M 34 182
제시카 F 26 171
노규태 M 42 174
홍자영 F 43 163
향미 F 34 168
강필구 M 8 135
;
RUN;
PROC SUMMARY DATA=sampledata8 NWAY;
CLASS sex;
VAR height;
OUTPUT OUT=sampledata9 MEAN(height)=mean_h;
RUN;
PROC PRINT DATA=sampledata9;
RUN;
/**Example: PROC SORT/PROC PRINT**/
PROC SORT DATA=sampledata8 OUT=sampledata10;
BY sex DESCENDING age;
RUN;
PROC PRINT DATA=sampledata10;
BY sex;
RUN;

변수 생성 및 변환 프로시저
RANK - 숫자 변수의 순위 부여
PROC RANK DATA=sampledata8 OUT=sampledata11 TIES=LOW;
VAR age height;
RANKS age_r height_r ;
RUN;

STANDARD - 숫자 변수의 표준화
PROC STANDARD DATA=sampledata8 OUT=sampledata12 MEAN=0 STD=1;
VAR height;
RUN;
PROC MEANS DATA=sampledata8 mean var;
VAR height;
RUN;


Data Set Option
KEEP = variable [variable]: 포함할 변수들 지정DROP = variable [variable]: 제외할 변수들 지정RENAME = (old_Name = New_Name [old_Name = New_Name]: 기존 변수 이름 변경FIRSTOBS = n: 읽어들일 시작점 설정OBS = n: 읽어들일 끝점 설정IN = variable: 관측치가 어느 Data Set에서 왔는지 나타내는 1과 0값을 갖는 변수 생성
Data Set 결합
세로 결합 - SET
- 둘 이상의 Data Set이 같은 변수에 대해 서로 다른 관찰 값을 가지고 있는 경우
- 기존 자료에 새로 얻은 관찰값 추가

DATA new_data_set;
SET dataset1 dataset2;
가로 결합 - MERGE, UPDATE
- 둘 이상의 Data Set이 같은 관찰 값에 대해 새로운 변수를 추가하는 경우
- 기존 자료에 새로운 변수 추가
- MERGE : 동일한 변수 이름에 같은자료가 있으면 나중에 언급된 자료로 대체
- UPDATE :뒤의 값이 결측값이면 기존 자료 값 유지
- 특정 변수에 대해 MERGE 또는 UPDATE 명령 수행하는 경우 BY 명령문 사용할 수 있으며, 이 경우 사용되는 모든 Data Set이 PROC SORT를 이용해 사전 정렬되어야 함
- IF명령문 함께 사용 가능

DATA new_data_set; MERGE(UPDATE) dataset1 dataset2;`
BY var1 var2; 'STATISTICS > SAS' 카테고리의 다른 글
| Code _ Linear Regression (0) | 2020.03.09 |
|---|---|
| 비교분석 코드 예제 (0) | 2020.03.06 |
| Plots (0) | 2020.03.05 |


