객체 탐지(Object detection)은 어떤 객체(Label)가 어디에(x, y) 어느 크기로(w, h) 존재하는지 찾는 Task

Classification + Localization(Bounding Box)
- Classification
- Localization -> regression
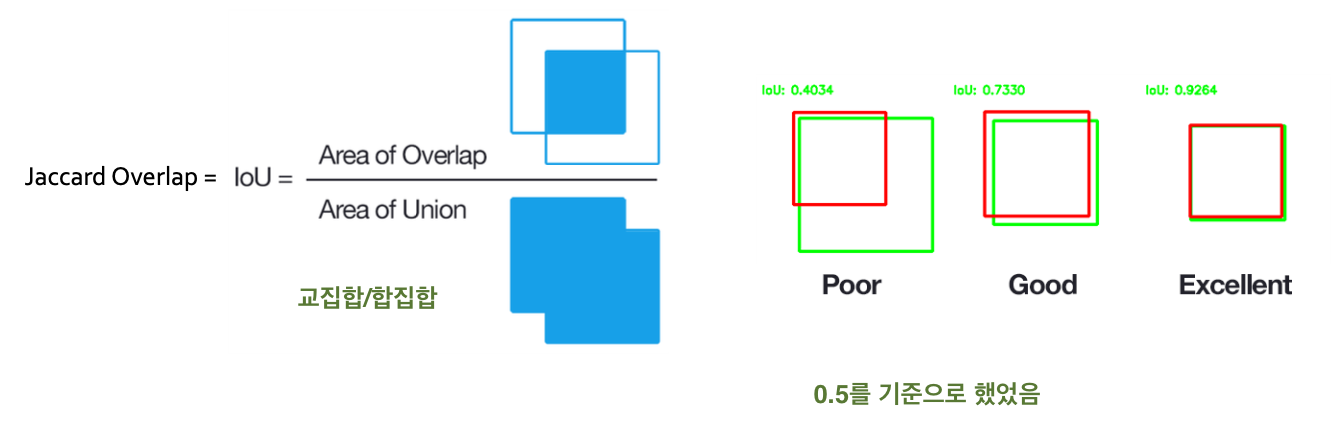
- 평가: intersection over union
Two-stage Method
R-CNN : Regions with CNN features

1. Hypothesize Bounding Boxes (Proposals)
- Object가 존재할 적절한 위치에 Bounding Box Proposal (Selective Search)
- 2000개의 Proposal 생성
2. Resampling pixels / features for each boxes
- 모든 Proposal을 Crop 후 동일한 크기로 만듦 (224x224)
3. Classifier / Bounding Box Regressor
- Classifier와 Bounding Box Regressor로 처리
하지만 모든 Proposal에 대해 CNN을 거쳐야 하므로 연산량이 매우 많은 단점이 존재
Selective Search
- Segmentation : 이미지 구조적 특징(색상, 무늬, 크기, 모양)을 사용하여 후보 영역을 추출
- Exhaustive Search : 모든 가능한 후보 영역을 검색
1. 초기 후보 영역을 다양한 크기와 비율로 생성
2. 알고리즘을 통해 비슷한 영역을 반복적으로 통합하여 비슷한 영역간에 점점 통합이 되도록 함
3. 최종적으로 하나의 영역이 만들어질 때까지, 2번 반복적으로 수행하면서 각 후보 영역들이 유사도가 높은 영역간 통합
- 후보 영역 추출 과정이 CNN과 별도로 동작하기 때문에 보틀넥이 발생 -> Faster R-CNN, YOLO, FCN 등은 end-to-end 학습이 가능하도록 개선
Training

Fast R-CNN
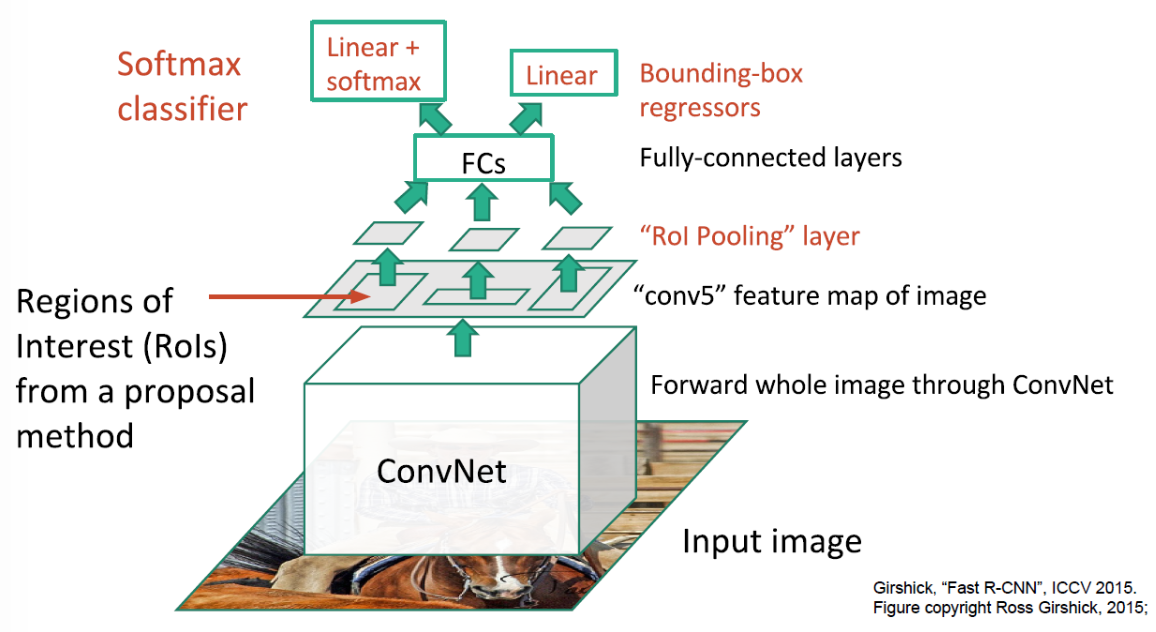
- 모든 Proposal이 네트워크를 거쳐야 하는 R-CNN의 병목(bottleneck)구조의 단점을 개선하고자 제안된 방식
- 각 Proposal들이 CNN을 거치는것이 아니라 전체 이미지에 대해 CNN을 한번 거친 후 출력된 feature map에서 객체 탐지 수행
- 시간 오래걸리는 2000개를 CNN하지 않고 통으로 하나만 집어넣어서 projection
- 기존 연산량: R-CNN이 selective search * CNN
- Fast R-CNN 연산량: (selective search + RoI Pooling) * 1
- 하지만 Fast R-CNN에서 Region Proposal을 CNN Network가 아닌 Selective search 외부 알고리즘으로 수행하여 병목현상 발생
ROI Pooling
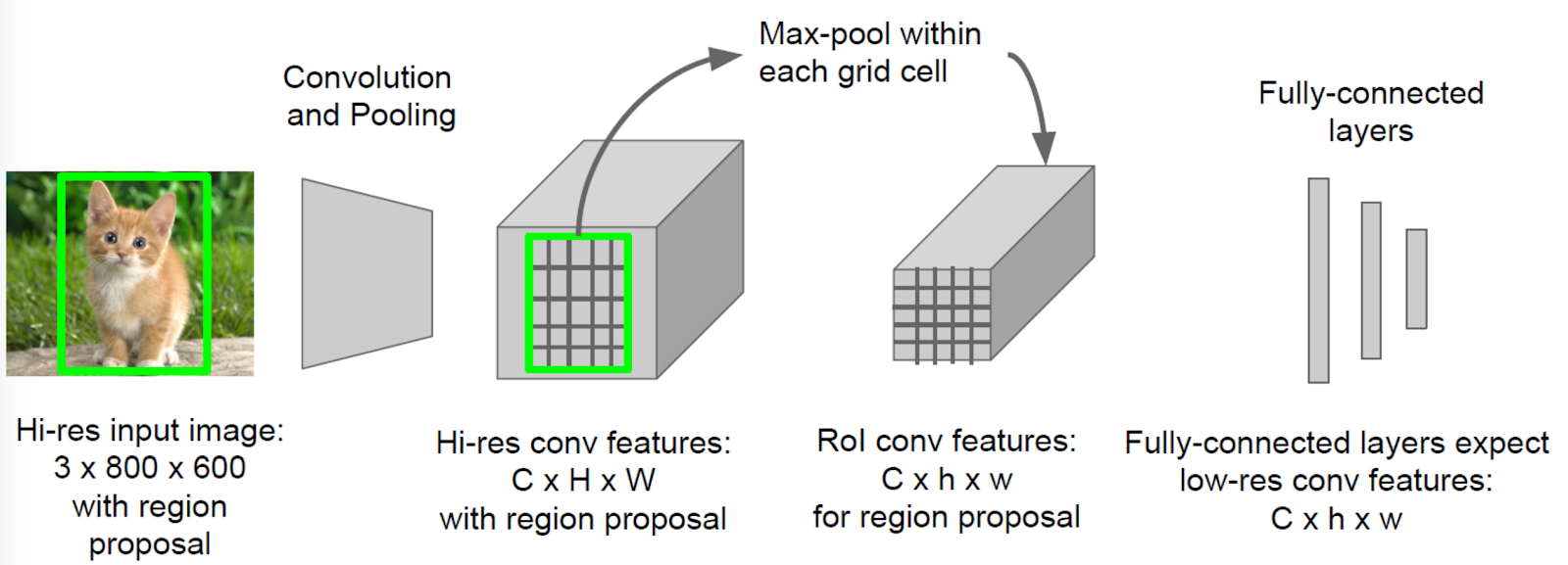
어떠한 RP가 들어오더라도 max pooling을 이용하여 결과의 output size가 같도록 하는 것
여기서 성능저하 발생:
1. CNN 통과시키면서 사이즈 줄어들때 (1/32로 줄일때) 정수로 보정하면서 오차 발생
- 반올림하면 최대 0.5px 차이, 원본에서 16px 까지 차이날 수 있음
- 마스크 R-CNN에서는 (인스턴스 세그멘테이션)때에 이 문제 해결
2. 안떨어지는 경우 걍 불균형하게 자름
faster R-CNN

Region Proposal을 RPN(Region Proposal Network) 네트워크 이용하여 병목현상 해소
- 기존의 Selective search 가 아닌 CNN(RPN)으로 해결
- CNN을 통과한 Feature map에서 슬라이딩 윈도우를 이용해 각 지점(anchor)마다 가능한 바운딩 박스의 좌표와 그 점수를 계산
- 2:1, 1:1, 1:2의 종횡비(Aspect ratio)로 객체를 탐색
One-stage Method
YOLO (You Only Look Once)
- 바운딩 박스와 그에 해당하는 클래스(셀 안에서) 동시에 찾음
- Detection 문제를 Regression 문제로 접근
- 원본 이미지를 동일한 크기의 그리드로 나눔
- 그리드 중앙을 중심으로 미리 정의된 형태(predefined shape)으로 지정된 경계박스의 개수 예측
- 높은 객체 신뢰도를 가진 위치를 선택해 객체 카테고리 파악
- 한 셀안에 중심이 둘 이상 들어가 있는 경우 하나만 찾으므로 리콜이 떨어짐
- 백그라운드가 없음 -> 컨피던스로 조절
- 선이 굵을수록 컨피던스 높음
- 바운딩박스를 98개만 뽑게됨
- feature map을 다양하게 하므로 앞에서 작은 물체 뽑고 뒤에서 큰 물체를 뽑는것이 가능
- 전체 이미지를 한번에 처리하므로 매우 빠름
- 바운딩 박스의 위치가 정확하지 않고, 작은 이미지가 붙어있는 경우 적합하지 않음
- 스코어 측정시 좋지 않음
Loss function
- classification loss
- localization loss (errors between the predicted boundary box and the ground truth)
- confidence loss (the objectness of the box)
SSD (Single Shot multi box Detector)
- YOLO의 컨셉과 Faster RCNN region proposal network를 합친 것
- Single Shot: object proposals이 없이 한번에! convolution feature map의 grid마다 나오는 것
- 검출 속도와 정확도 사이의 균형이 있는 알고리즘
- 한 번 입력된 이미지에 대한 CNN을 실행하고 feature map 계산
- 다양한 스케일의 물체 검출

'DEEP LEARNING > Fundamental Concept' 카테고리의 다른 글
| RNN (0) | 2020.03.31 |
|---|---|
| Semantic Segmentation (0) | 2020.03.30 |
| Modern CNN (0) | 2020.03.10 |
| Convolutional Neural Network (0) | 2020.03.03 |
| Training Neural Networks (0) | 2020.02.24 |



